I’ve seen this across many companies I’ve both worked in and consulted for throughout my career — we’re not hiring the right people for the job!
I still hear a lot of horror stories of data science teams underperforming, management losing confidence in data science in general, or data scientists getting frustrated in their roles. When you take a deeper look, you see a common pattern.
We keep hiring data scientists without really understanding where they bring the most value.
For many organisations, it’s analysts and data engineers that are really what’s needed. Sometimes, it’s not even data or insights that are at the core of the work and you’re much better off with software engineers and developers.
Data scientists have a dangerous combination of attributes that exacerbate this issue:
- A broad skill-set means data scientists typically do have the foundational capabilities to tackle most problems — albeit slower and more expensively than some specialists.
- A career that rewards the naturally curious means that many data scientists will be keen to explore challenges that should sit firmly outside of the scope of their role.
- Competition to land a data science role will, for some, mean that they remain eager to please and happy to pick up tasks not quite suited to them in order to be a good citizen.
- Lack of experience in early career data scientists and management, coupled with a confusing, poorly defined role (no one seems to agree on what a data scientist is/isn’t) leads to a misallocation of resources to the right tasks.
The list could go on. I’m not surprised then when I meet data scientists that have done nothing but BI or foundational database development for the last 18 months — tasks that a specialist would be much better suited for.
There’s a large mismatch between what organisations need to be delivered and the skills they bring in to do the job.
You Probably Need an Analyst
Are you doing experimentation to steer the business and make change, or supporting the day-to-day decision making in the business?
It’s hard to know what the right mix of skills are — it’s rarely done right and the specifics around each organisation, industry, function, team, and individual personalities mean that there’s never going to be a simple formula to work this out. In general, though, you need more analysts — hiring data scientists to build basic reports on business metrics isn’t the best use of skills and resources.
Statisticians are a rarer breed these days. There are many out there doing great work and it’s these skillsets that organisations crave. According to sites such as Glassdoor and Stack Overflow, the average data scientist salary is approximately 21% higher than the average statistician. Many data scientists are a jack of all trades and, therefore, it’s fairly easy for someone with a strong grounding in statistics to pick up the basics of data management and processing and land themselves a significant pay rise.
Getting the new job is only half the problem though. The newly found statistician turned data scientist finds themselves in a completely different world — there’s a reason many of these data scientists have such a broad skillset. The vast majority of your day was previously spent running statistical models, interpreting data, building reports to deliver insights from company data. Now, with your 20% pay rise, you’re spending almost all of your time sourcing data, building data pipelines, writing simple reports and slide decks, crafting SQL to get at the basic stuff you need to even begin the analysis. This isn’t where the core of your skill lies. You’re now doing the work of an entry-level data analyst supporting day-to-day business functions with simple analyses and reporting because the right people aren’t there to do it.
The major difference between the value from an analyst compared to a statistician or data scientist. Analysts are absolutely essential for making sure the right insights and information is put in the hands of the right people at the right time. Day in, day out. Most organisations find themselves in a Hell of Excel spreadsheets — analysts are there to guide people back to sanity.
Data scientists and statisticians, however, should be providing longer-term transformational services. Unlocking brand new understanding, crafting experiments to test new hypotheses, developing predictive capabilities and brand new models as part of longer-term research initiatives. Having the ability to do this well is why the data science role pays more — it should take significant time and practice to acquire these skills. It’s what makes a data scientist useful to an organisation even without having a deep understanding of the industry.
Neither is better than the other, they both have their place and serve different purposes.
The convergence of so many skilled and nuanced job roles into the murky waters of data science has led many organisations to suffer. These skilled workers may now be making more money but doing a job that isn’t anywhere near as fulfilling as where they were before. Furthermore, the organisation is paying over the market value for the skills it truly needs and might even be getting someone less skilled at the specific task.
You Probably Need a Data Engineer
Back when I started doing data science it was far less common to hear about data engineers. If you look at the Google Trends chart below you’ll see the difference in popularity (hype) and how the term ‘Data Engineer’ in red didn’t really get off the ground until about 2014 in relation to ‘Data Scientist’ in blue. There was certainly a lot of discussion around data engineering and many data scientists (myself included) pretty much had to do all of their own.
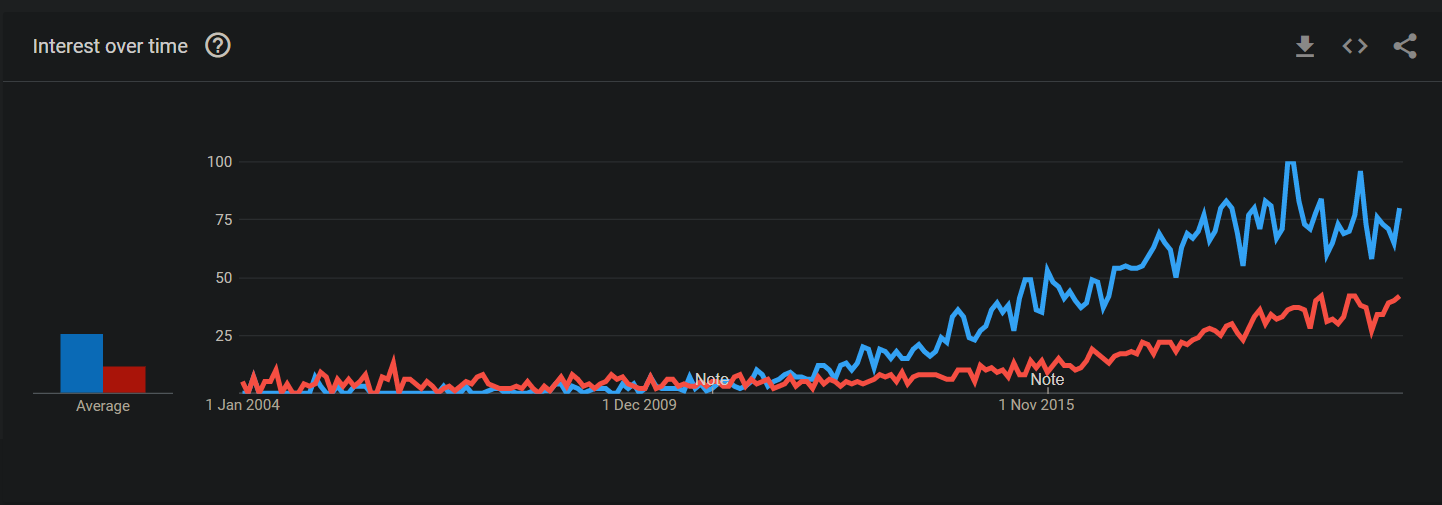
Data Scientist' in blue vs. 'Data Engineer' in red (source).
It’s no longer 2014, though. In fact, I’m surprised there’s still as much of a gap today as there is.
The vast majority of organisations would be better off hiring data engineers over data scientists.
Having a data scientist in the doors early can really help to shape some of the needs around the data and analytics functions as they’ll typically touch on many areas of the business. Data scientists are often great with a loose scope and soft requirements. When the asks are known though, you very quickly land in a place where there’s a boat-load of data management and processing to do.
Getting the foundations of a data platform in place can take months for even the simplest of requirements. As your platform grows new requirements will surface and the maintenance overhead will increase. I strongly recommend getting a good data engineer in the door as early as possible. Although many data scientists make good data engineers, you usually get a mixed bag of both skill and awareness around the best practices when architecting and designing data solutions. Furthermore, data engineers tend to be better when it comes to integrating solutions with CI/CD, building tests, and all that good engineering stuff we’ve come to rely on for growing tech stacks — because data scientists should really be focusing on one-offs and experimentation to deliver the most value.
There’s a lot of value to be had from strong data engineering to support functions across the business too. Many data engineers come from BI backgrounds and have a detailed understanding of the data needs of business users and analysts.
You Probably Need a Software Engineer
It’s becoming increasingly more common to have advanced analytics and machine learning at the heart of larger-scale applications. This leads to data teams being at the very core of the development process, shaping the path of the application and delivering it alongside other teams.
This is where many organisations fall down though.
Just because there is some machine learning in an application doesn’t mean you need a team of only data scientists. Data scientists aren’t (or at least shouldn’t be) there to develop robust, scalable, interactive, shippable software. The most value you can get from a data scientist is by giving them a question with a clear, measurable deliverable and some data and letting them iterate their way to some sort of answer. Sure, they’ll be crucial in translating and handing over any rough, proof of concept solution to the wider team. Baking them in as a dependency for the wider project is another gross misallocation of resources.
What you really need are strong teams of software engineers. Yes, a data scientist can probably knock up some sort of interactive GUI, but it’ll be much better if handled by front-end developers. Yes, data scientists can build you a pipeline that’ll get the data from source to sink, but back-end developers, data engineers, and testers are going to make something far more robust and scalable.
You don’t need to understand how to model works to make it into a shippable, scalable piece of software that plays nicely with the rest of your application.
Let your data scientists focus on the question led, science aspects of the work and leave the engineering to the engineers.
You’ll get more engagement, satisfaction, more performant code, stronger collaboration, catch more edge cases, get less stepping on toes and frustrations. Data scientists can be essential in some circumstances but can be outright obstacles in others.
Final thoughts
With so many people keen to become data scientists we’ve lost some of the nuances of other data-related roles. Furthermore, many hiring managers don’t have the understanding or the experience yet to know what a good data scientist can contribute or when one is needed. This leads to many people being in the wrong roles and frustration all around.
Next time you’re keen to fire up a new job advert for a data scientist really think — what’s the core of this role? Will they be doing research and science, shaping the future direction of travel, or will they be doing foundational engineering or supporting the business as usual?
This blog originally appeared on https://adzsroka.medium.com/
Author Bio
Dr Adam Sroka, Head of Machine Learning Engineering at Origami Energy, is an experienced data and AI leader helping organisations unlock value from data by delivering enterprise-scale solutions and building high-performing data and analytics teams from the ground up. Adam shares his thoughts and ideas through public speaking, tech community events, on his blog, and in his podcast.